Abstract
Contrastive learning applied to self-supervised representation learning has seen a resurgence in deep models. In this paper, we find that existing contrastive learning based solutions for self-supervised video recognition focus on inter-variance encoding but ignore the intra-variance existing in clips within the same video. We thus propose to learn dual representations for each clip which (1) encode intra-variance through a shuffle-rank pretext task; (2) encode inter-variance through a temporal coherent contrastive loss. Experiment results show that our method plays an essential role in balancing inter and intra variances and brings consistent performance gains on multiple backbones and contrastive learning frameworks. Integrated with SimCLR and pretrained on Kinetics-400, our method achieves 82.0% and 51.2% downstream classification accuracy on UCF101 and HMDB51 test sets respectively and 46.1% video retrieval accuracy on UCF101, outperforming both pretext-task based and contrastive learning based counterparts.
Limitation of Contrastive Learning
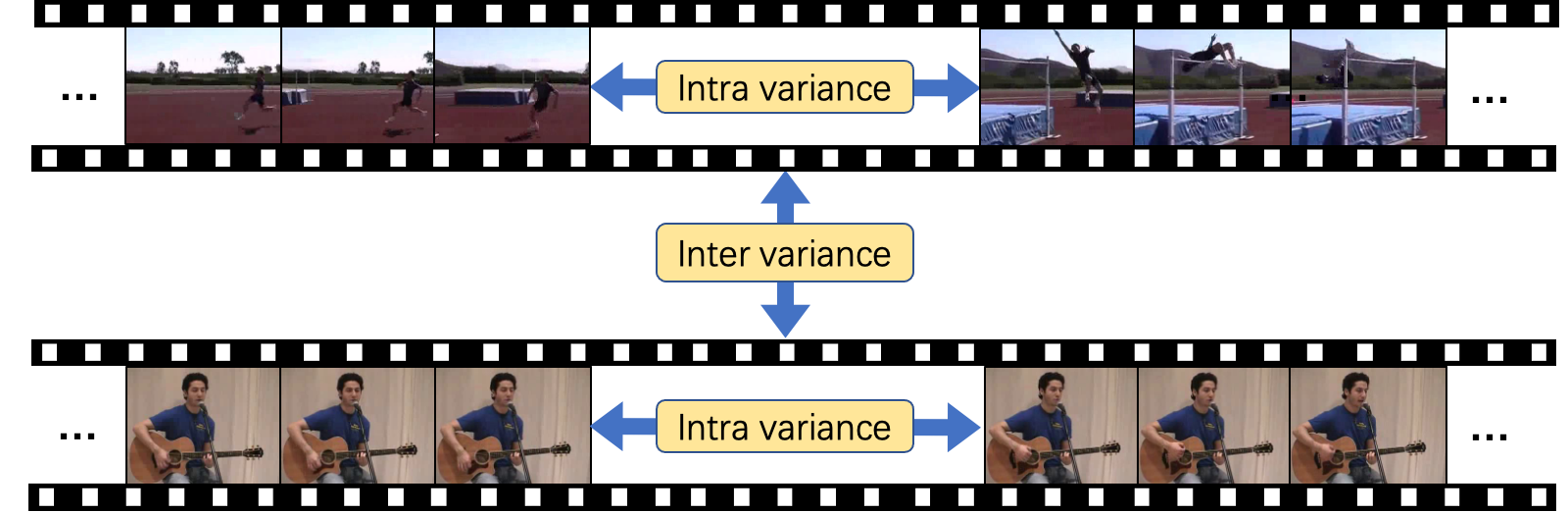
Video semantics rely on not only image-level appearances, but also the temporal variance, i.e. different clips sampled from different time spans of a video exhibit different semantics meanings. For instance, \emph{running} and \emph{jumping} are two different mini-actions though they are both sampled from a video classified as \emph{HighJump}. However, contrastive learning overemphasizes the learning of inter-variance but ignores intra-variance.
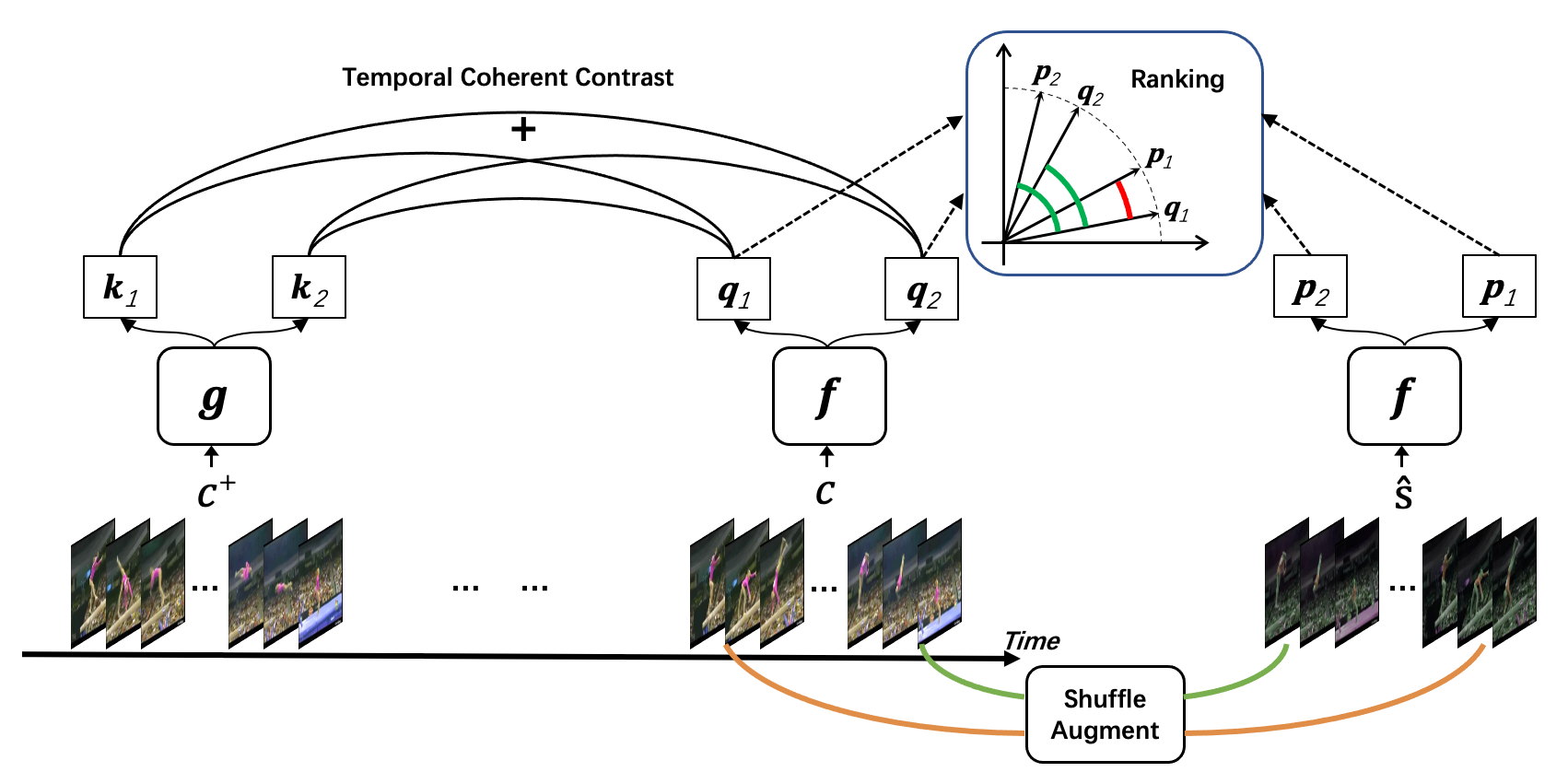
Methodology
Our method learns dual representations for each clip. which encode not only intra-variance between sub-clips but also inter-variance between different videos. We realize that intra-variance can be subtle depending on different videos and a large-margin-induced classification loss will thus spoil inter-variance encoding.To learn the subtle intra-variance, we adopt a ranking loss to induce a small margin between sub-clip features. We then apply temporal coherent contrastive loss on the same set of sub-clip features to jointly learn inter-variance.
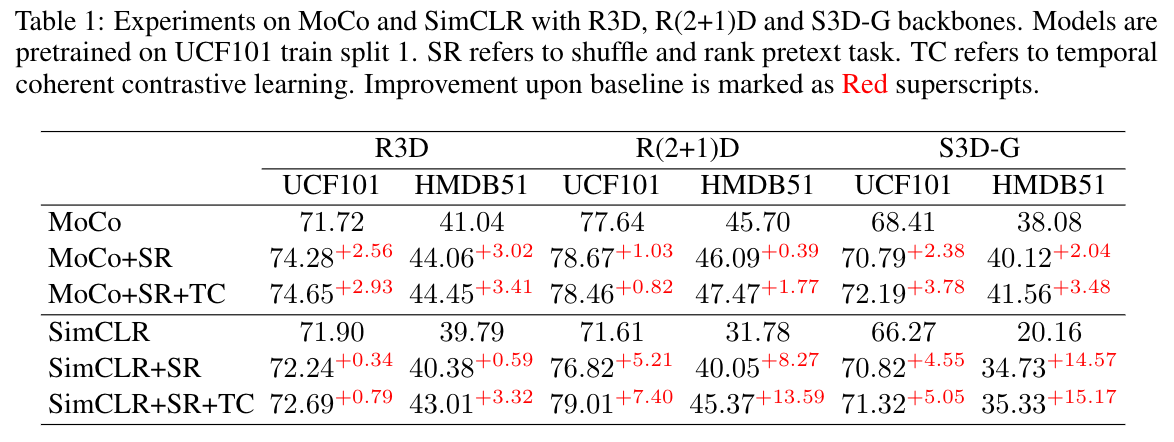
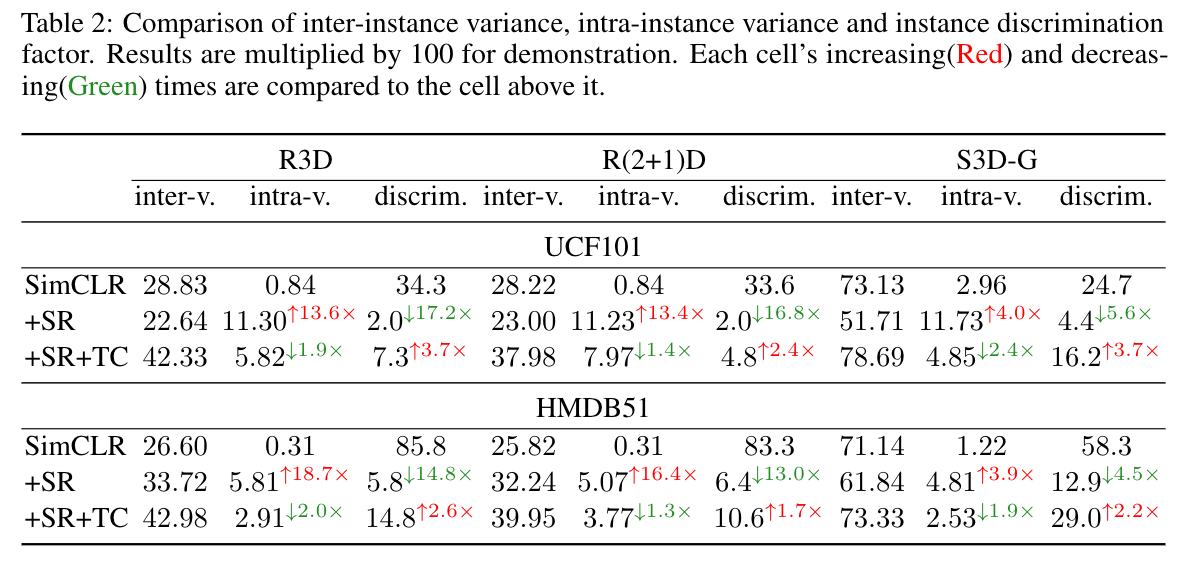
Performance Comparison
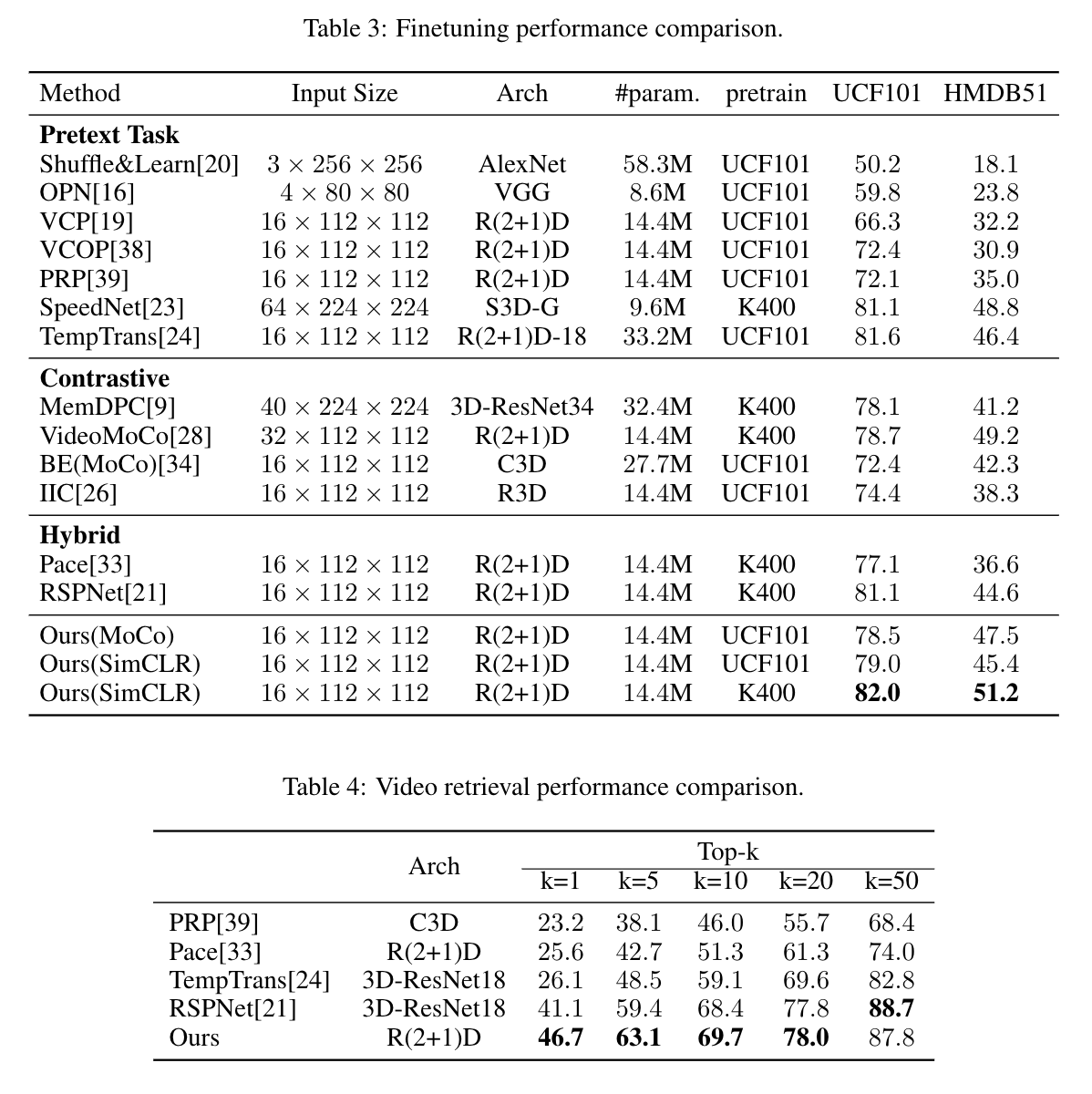
Feature Distribution
Feature distribution of baseline SimCLR is very sparse, with large margin between different classes. With our shuffle-rank (SR) pretext task, intra-variance becomes larger, resulting in a denser distribution. Further equipping the model with temporal coherent (TC) contrastive loss makes the clustering borders clearer.
SimCLR
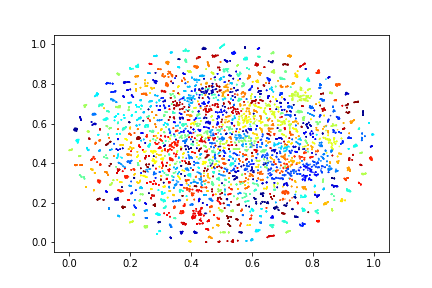
+SR
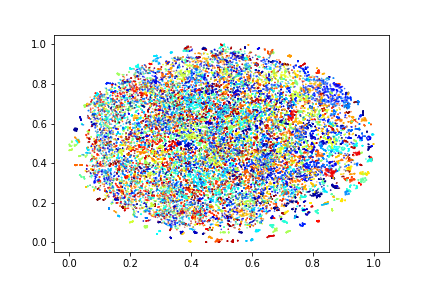
+TC
Video Retrieval Visualization
